Stress Testing / Performance Testing
Diseñamos y ejecutamos pruebas de stress y performance para sistemas críticos. Simulamos carga real, instrumentamos monitoreo y ayudamos al equipo de IT a identificar cuellos de botella y validar correcciones con evidencia comparable.
En subastas online, e-commerce, sistemas contables o plataformas críticas, una degradación de performance impacta directamente en ingresos y reputación de marca.
Además, muchas industrias tienen fechas y eventos críticos que exigen al máximo la capacidad de sus sistemas. Empresas de venta de artículos para el hogar o electrónica experimentan picos significativos en fechas como Día de la Madre, campañas especiales o promociones estacionales. Plataformas de comercio electrónico enfrentan eventos como Cyber Monday, Black Friday o lanzamientos masivos.
En estos contextos, el sistema no puede fallar. Idealmente, al menos 15 días antes de una fecha crítica, la organización debería contar con evidencia concreta de que la infraestructura y la aplicación soportarán la carga esperada sin degradación ni interrupciones.
Cada industria tiene su propio calendario de alta exigencia: cierres contables, campañas comerciales, eventos de subasta en vivo, vencimientos fiscales, promociones coordinadas con medios o influencers. Las pruebas de stress permiten anticipar el riesgo y llegar a esos momentos con previsibilidad.
Un stress test no es solo una prueba técnica: es una herramienta de gestión de riesgo para proteger ingresos, reputación y continuidad operativa en los momentos donde más está en juego.
Elegimos la herramienta más apropiada según el tipo de sistema, arquitectura y objetivos.
Ejecutamos pruebas de stress de forma controlada, medible y repetible, trabajando en conjunto con IT para identificar el problema y verificar la solución con evidencia comparable.
Dashboards típicos de ejecución: volumen de mensajes, usuarios concurrentes, latencia end-to-end, estabilidad del stream y pérdida de confirmaciones.
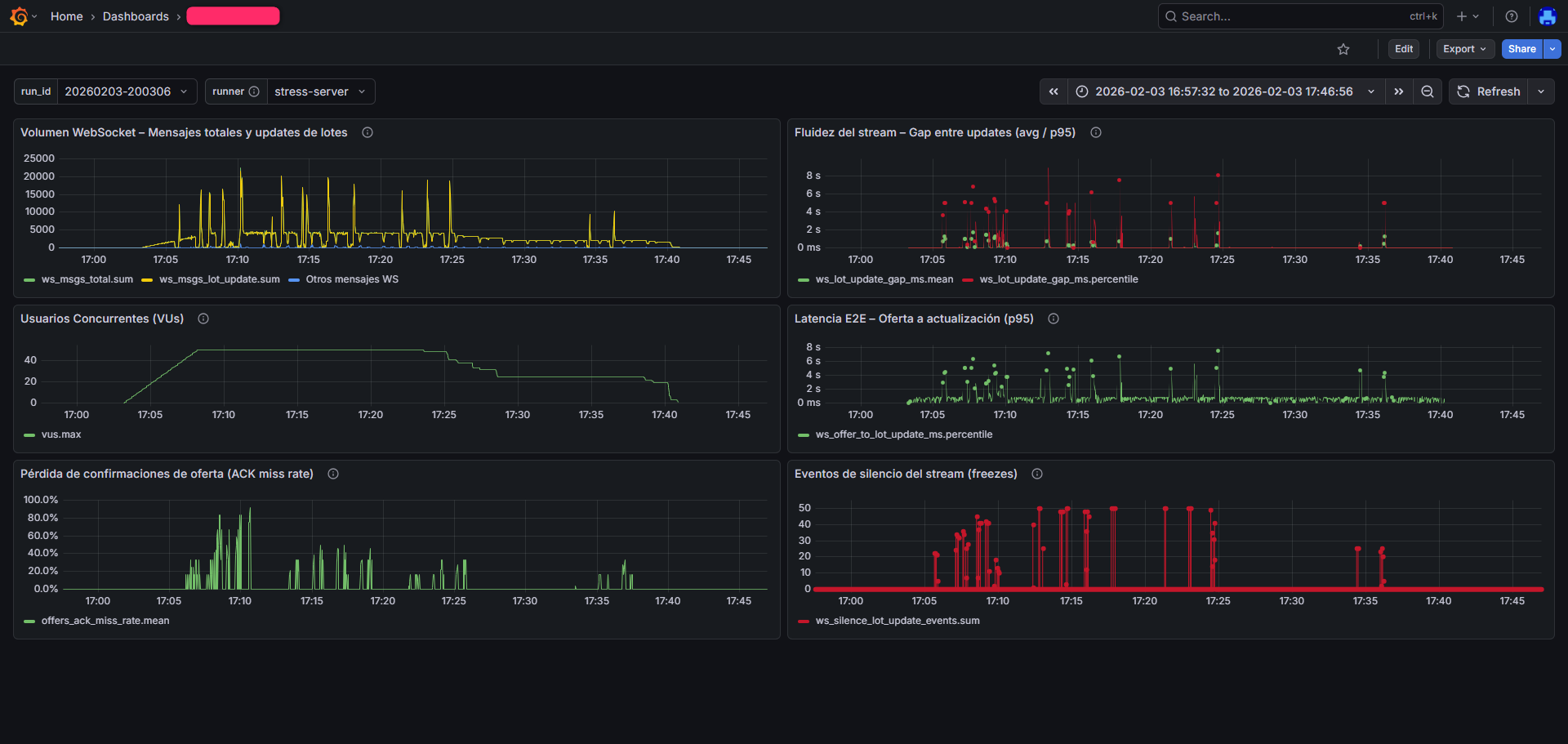
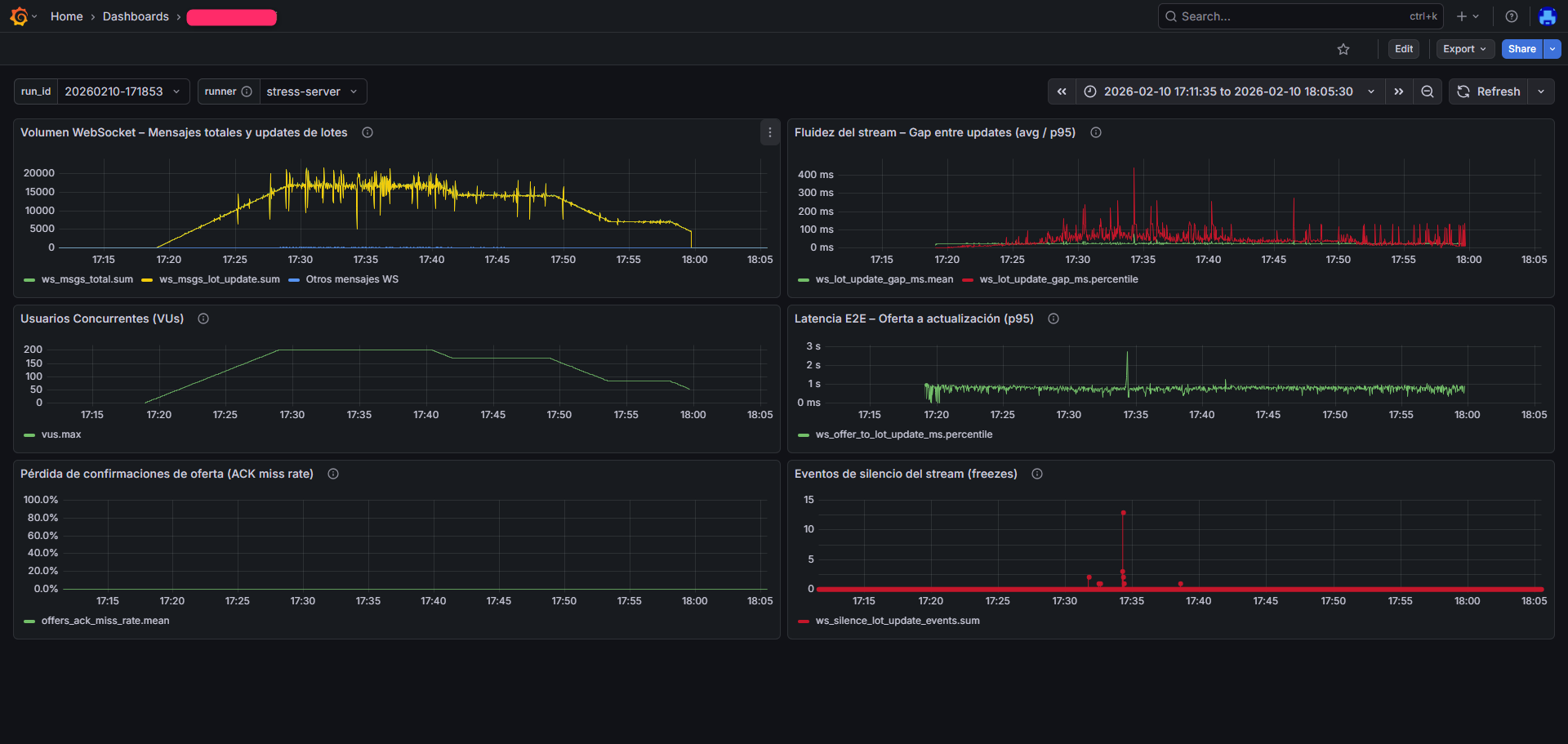
Nota: se muestran métricas representativas sin exponer información sensible del cliente.
Hemos ejecutado pruebas de stress en industrias donde el rendimiento impacta directo en ventas y operaciones.
Día de la Madre, Cyber Monday, Black Friday, cierre contable,
subasta en vivo, campaña promocional o lanzamiento de producto.
Si el sistema falla en esos momentos, el impacto no es técnico.
Es económico.
Contanos brevemente el escenario y coordinamos una conversación técnica. Si ya tienen un evento o pico estimado, incluilo: ayuda a diseñar el test con precisión.